Python et Format CSV
Crédit
Cette séance est largement inspirée de celle de David Roche. Merci à lui.Compte-rendu
Un compte-rendu numérique, à rendre sur Pronote, est attendu à la fin de la séance. Il devra impérativement être rendu au format PDF (un point sera enlevé à la note finale si un autre format est utilisé).Répondez sur ce compte-rendu aux questions marquées d'un crayon : ✏️.
Format CSV
Voici le contenu d'un fichier informaticiens.csv, au format CSV.
Nom,Prénom,Date de naissance Jacquard,Joseph-Marie,07/07/1752 Boole,George,02/11/1815 Lovelace,Ada,10/12/1815 Church,Alonzo,14/06/1903 Turing,Alan,23/06/1912 Hamilton,Margaret,17/08/1936 Vaughan,Dorothy,20/09/1910 Hopper,Grace,9/12/1906
Répondez aux questions suivantes très rapidement, sans noter les réponses.
Que signifient les initiales du format de fichier
.csv? Donner la signification anglaise, et sa traduction en français. Cherchez la réponse à cette question sur Internet.La première ligne du fichier correspond aux descripteurs, c'est-à-dire aux titres des colonnes de classement.
- Quels sont les trois descripteurs de ces données ?
- Quel symbole est utilisé comme séparateur ?
Analyse du fichier « à la main ». Toutes les réponses à ces questions sont à lire dans le fichier.
- En quelle année est née Ada Lovelace ?
- Quel est le prénom de Mme Hamilton ?
- Qui, parmi les personnes listées dans ce fichier, est né le plus tard ?
Préparation du compte-rendu
- Ouvrez le traitement de texte LibreOffice (vous pouvez utiliser Microsoft Word si vous préférez, mais je ne pourrai pas vous aider dans son utilisation).
- Écrivez vos noms, la date, le titre de la séance.
- Enregistrez le document dans votre répertoire personnel.
Exemple pas à pas
Un tout petit fichier comme celui étudié dans la première partie est simple à manipuler avec un éditeur de textes, mais cela devient plus compliqué pour de gros fichiers.
Téléchargement du fichier
- Télécharger le fichier des prénoms : sur cette page, téléchargez France (y compris Mayotte depuis 2013) au format
csv. - Ouvrez le fichier
.zipainsi obtenu, et extrayez le fichierprenoms-2023-nat.csv, que vous enregistrez dans votre répertoire personnel.
Préparation de Thonny
- Ouvrez le logiciel Thonny.
Recopiez le programme suivant dans Thonny, et enregistrez-le dans le même dossier que le fichier
.csvde la question précédente.import pandas prenoms = pandas.read_csv("prenoms-2023-nat.csv", sep=";") print(prenoms)
Exécutez ce fichier, et regardez le shell (le bas de la fenêtre de Thonny).
- Si vous voyez afficher un tableau, le programme s'est exécuté sans erreur : passez à la question suivante.
- Si une erreur apparaît, essayez de la comprendre et de la corriger. Appelez le professeur si nécessaire.
Parcours du tableau
Analysons le tableau affiché dans Thonny à la question précédente (remarque : le fichier étant mis à jour chaque année, il est possible que vous n'obteniez pas exactement les mêmes résultats que ceux présentés ici).
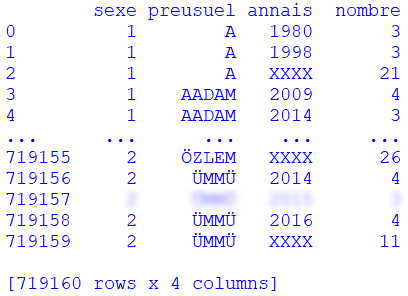
La première ligne correspond aux descripteurs du fichier :
sexe: sexe du prénom (1 pour un garçon ; 2 pour une fille) ;preusuel: prénom ;annais: année de naissance (attention : il s'agit de l'année de naissance, et non pas du prénom Anaïs) ;nombre: nombre d'enfants portant ce prénom.
Certaines valeurs (pour les années) sont égales à
XXXX. Cela correspond sans doute à des données incorrectes ou inconnues.Chaque ligne suivante correspond à une données différente. Par exemple, la ligne numéro 719156 (deuxième en partant de la fin) signifie :
En 2016, on a donné le prénom Ümmu à quatre filles.
✏️ La ligne 719157 de la capture d'écran ci-dessus a été cachée. Retrouvez-là dans, et recopiez-la dans son intégralité dans le compte-rendu (vous pouvez faire un copier-coller pour gagner du temps).
✏️ Complétez la phrase suivante avec les données de la ligne copiée-collée à la question précédente.
En ????, on a donné le prénom ???? à ??? filles/garçons.
Nettoyage du tableau, et calcul des effectifs par année
Le tableau contient de nombreuses lignes avec des valeurs invalides : des XXXX à la place de l'année, ou les prénoms peu donnés regroupés sous la mention _PRENOMS_RARES.
Le code suivant permette cela.
import pandas fichier = pandas.read_csv("prenoms-2023-nat.csv", sep=";") prenoms = fichier.loc[(fichier["annais"] != "XXXX") & (fichier["preusuel"] != "_PRENOMS_RARES")] print(prenoms)
- Recopiez et exécutez ce programme.
- ✏️ Combien de lignes contient alors le tableau (indice : dans un tableau, « ligne » se dit « row » en anglais) ?
Recherche dans le tableau
Nous allons maintenant faire des recherches dans cette base de données.
Recopier le programme suivant dans Thonny, et exécutez-le.
import pandas fichier = pandas.read_csv("prenoms-2023-nat.csv", sep=";") prenoms = fichier.loc[(fichier["annais"] != "XXXX") & (fichier["preusuel"] != "_PRENOMS_RARES")] # NE PAS MODIFIER LES LIGNES DU DESSUS recherche = prenoms.loc[(prenoms['annais'] == "1985"), :] print(recherche)
Vérifiez que ne sont affichés que les prénoms donnés en 1985.
Dans le programme précédent, remplacez la ligne commençant par
recherche = prenoms.loc…par :recherche = prenoms.loc[(prenoms['preusuel'] == "HUGO"), :]
Exécutez le programme, et vérifiez que ne sont affichés que les prénoms Hugo.
Enfin, il est possible de combiner les conditions. Remplacez encore la troisième ligne (
recherche = …) par :recherche = prenoms.loc[(prenoms['sexe'] == 2) & (prenoms['preusuel'] == "CAMILLE"), :]
Exécutez-le, et vérifiez que ne sont affichés que les prénoms donnés aux filles nommées Camille (en excluant les garçons nommés Camille).
Il est possible aussi de trier les résultats. Ajoutons cela à la dernère recherche :
import pandas fichier = pandas.read_csv("prenoms-2023-nat.csv", sep=";") prenoms = fichier.loc[(fichier["annais"] != "XXXX") & (fichier["preusuel"] != "_PRENOMS_RARES")] # NE PAS MODIFIER LES LIGNES DU DESSUS recherche = prenoms.loc[(prenoms['sexe'] == 2) & (prenoms['annais'] == "1985"), :] tri = recherche.sort_values(by="nombre") print(tri)
Dans cet exemple, on recherche les prénoms donnés aux filles en 1985, et on trie les résultats par effectif. Cela permet de voir quels étaient les prénoms les plus donnés aux filles en 1985.
Répondre à cette question en modifiant le programme qui est actuellement ouvert dans Thonny.
Si vous travaillez par deux ne répondez à ces questions que pour l'un·e seul·e des deux élèves. Si vous ne vous identifiez ni comme garçon ni comme fille, choisissez un sexe de manière arbitraire pour répondre aux questions suivantes (par exemple, celui qui vous a été attribué à la naissance).
⚠️ Pour faire des recherches, les noms doivent être écrits en majuscule, en respectant les accents. Voici quelques lettres accentuées en majuscule que vous pouvez copier-coller pour rechercher votre prénom :
Á À Ä Â Ç É È Ë Ê Í Ì Ï Î Ó Ò Ö Ô Ú Ù Ü Û Ý Ỳ Ÿ Ŷ- ✏️ En quelle année êtes-vous né·e ?
- ✏️ Durant votre année de naissance, quels ont été le prénom le plus donné aux filles, et le prénom le plus donné aux garçons ?
- ✏️ Durant votre année de naissance, combien d'enfants de votre sexe ont été nommés avec le même prénom que vous ?
- ✏️ En quelle année votre prénom a-t-il été le plus populaire pour les enfants de votre sexe ?
Graphiques
Il est possible de tracer l'évolution du nombre d'enfants nés avec un prénom donné au fil des années. Par exemple, le programme suivant permet d'afficher la courbe des naissance des garçons portant le prénom Maurice.
import pandas import matplotlib.pyplot as plt fichier = pandas.read_csv("prenoms-2023-nat.csv", sep=";") prenoms = fichier.loc[(fichier["annais"] != "XXXX") & (fichier["preusuel"] != "_PRENOMS_RARES")] # NE PAS MODIFIER LES LIGNES DU DESSUS recherche = prenoms.loc[(prenoms['preusuel'] == "MAURICE") & (prenoms['sexe'] == 1), :] recherche.plot(x="annais", y="nombre") plt.show()
Recopiez et exécutez le programme précédent pour observer le graphique.
On remarque que le prénom était populaire entre 1900 et 1950 environ, mais n'est plus à la mode depuis.
✏️ On observe également une chute de la courbe peu avant 1920 et autour de 1940. Expliquer pourquoi.
✏️ Modifiez la ligne
recherche = …du programme pour tracer la courbe des naissances de votre prénom avec votre sexe au cours des années. Copiez cette courbe dans votre compte-rendu.- Si vous travaillez à deux, les deux courbes doivent apparaître.
- Si vous ne vous identifiez ni comme fille ni comme garçons, choisissez un genre arbitraire ou le genre qui vous a été attribué à la naissance.
Un peu plus d'autonomie
Téléchargez le fichier Moyennes par années et par chaînes sur le site
data.gouv.fr, et enregistrez-le dans votre dossier personnel.Recopiez le programme suivant dans un nouveau programme dans Thonny, et enregistrez-le dans le même répertoire que le fichier
.csvtéléchargé à la question précédente.import pandas parole = pandas.read_csv("20190308-years.csv") recherche = parole.loc[(parole['year'] == 2019), ["channel_name", "women_expression_rate"]] print(recherche)
Ce programme affiche, à partir des données téléchargées sur
data.gouv.fr, pour l'année 2019 et pour chacune des chaînes de radio et de télévision étudiée, la proportion du temps de parole des femmes. Par exemple, la ligne506 France 3 35.906998signifie : « En 2019, sur France 3, le temps consacré à la prise de parole (par opposition aux silences ou à la musique) a été pris par les femmes à 35,9 % (et donc par les hommes à 63,1 %) ».Ajoutez
["women_expression_rate"].mean()à la fin de la lignerecherche = …, et exécutez le programme. Il affiche alors la moyenne de la proportion du temps de parole par les femmes pour l'année 2019, pour l'ensemble des chaînes radio et télé étudiées1.✏️ Quelle est la moyenne de la proportion du temps de parole par les femmes pour les années 1999, 2009, 2019 ?
Ne donnez pas seulement la réponse, mais expliquer les modifications faites à votre programme pour obtenir cette réponse (ou copiez-collez le programme qui vous a permis de trouver la réponse).
✏️ La situation semble-t-elle être plus égalitaire au fil du temps ?
Enlevez le
["women_expression_rate"].mean()ajouté à la question précédente, et modifiez (si nécessaire) votre programme pour qu'il affiche les données de l'année 2019.✏️ En 2019, quelle est la chaîne dans laquelle le partage de la parole entre hommes et femmes a été le plus inégalitaire ? Le moins inégalitaire ?
Ne donnez pas seulement la réponse, mais expliquer les modifications faites à votre programme pour obtenir cette réponse (ou copiez-collez le programme qui vous a permis de trouver la réponse).
Rendu
- Vérifiez que vos deux noms apparaissent dans l'en-tête du document.
- Convertissez votre compte-rendu au format PDF.
- Rendez-moi le compte-rendu (celui au format PDF) sur Pronote.
Si nous voulons faire une analyse rigoureuse de ces données, les moyennes calculées à cette question ne sont pas vraiment pertinentes. Il aurait été plus juste de :
- calculer, pour chaque chaîne, le temps de parole des hommes et des femmes (possible grâce aux colonnes donnant la proportion de parole par rapport au reste (musique, silence), et le nombre d'heures analysées) ;
- en déduire le temps de parole total (pour l'ensemble des chaînes) des hommes et des femmes ;
- en déduire la proportion du temps de parole des femmes sur l'ensemble des chaînes.
Tout cela aurait été possible pour des élèves de seconde, en étant guidé. Cela aurait même constitué un travail intéressant. Mais nous ne disposons que d'une heure et demie par semaine, donc je suis obligé de faire des choix…↩